Apache NiFi Course Objects
- NiFi Introduction
- What is Apache NiFi
- Challenges of dataflow
- Capabilities of Apache NiFi
- Features of Apache NiFi
- NiFi core concepts
- Flow Files, Processors & Connectors
- NiFi Architecture
- NiFi Download & Installation
- Creating NiFi Process Flows Hands-on
- References
NiFi Introduction
What is Apache NiFi:
- NiFi is framework to automate the flow of data between systems.
- An easy to use, powerful, and reliable system to process and distribute data.
- Apache NiFi supports powerful and scalable directed graphs of data routing, transformation, and system mediation logic.
NiFi is built to help tackle the modern dataflow challenges.
Some of the high-level challenges of dataflow include:
- Systems fail, Networks fail, disks fail, software crashes, people make mistakes.
- Data access exceeds capacity to consume
- Boundary conditions are mere suggestions
- Invariably data that is too big, too small, too fast, too slow, corrupt, wrong, or in the wrong format.
- Priorities of an organization change – rapidly. Enabling new flows and changing existing ones must be fast.
- Systems evolve at different rates
- The protocols and formats used by a given system can change anytime
- Compliance and security: Laws, regulations, and policies change.
- Business to business agreements change.
- System to system and system to user interactions must be secure, trusted, accountable.
- Continuous improvement occurs in production
Some of the high-level capabilities and objectives of Apache NiFi include:
- Web-based user interface
- Provides visual creation and management of directed graphs of processors.
- Seamless experience between design, control, feedback, and monitoring
- Highly configurable
- Loss tolerant vs guaranteed delivery
- Low latency vs high throughput
- Dynamic prioritization
- Flow can be modified at runtime
- Back pressure
- Data Provenance
- Track dataflow from beginning to end
- Designed for extension
- Build your own processors and more
- Enables rapid development and effective testing
- Secure
- SSL, SSH, HTTPS, encrypted content, etc…
- Multi-tenant authorization and internal authorization/policy management
Features of Apache NiFi:
- Automate the flow of data between systems
- Eg: JSON -> Database, FTP -> Hadoop, Kafka -> ElasticSearch, etc…
- Drag and drop interface
- Focus on configuration of processor (i.e what matters only to user)
- Scalable across a cluster of machines
- Guaranteed Delivery / No Data Loss
- Data Buffering/ Back Pressure / Prioritization Queuing/ Latency vs Throughput
What Apache NiFi is good at:
- Reliable and secure transfer of data between systems
- Delivery of data from sources to analytics platforms
- Enrichment and preparation of data like
- Conversion between formats
- Extracting/Parsing
- Routing decisions
What Apache NiFi shouldn’t be used for:
- Distributed Computation
- Complex Event processing
- Joins, rolling windows, aggregate operations
NiFi Core concepts:

FlowFile: Each piece of “User Data” (i.e., data that the user brings into NiFi for processing and distribution) is referred to as a FlowFile. A FlowFile is made up of two parts: Attributes and Content. The Content is the User Data itself. Attributes are key-value pairs that are associated with the User Data.
Processor: The Processor is the NiFi component that is responsible for creating, sending, receiving, transforming, routing, splitting, merging, and processing FlowFiles. It is the most important building block available to NiFi users to build their dataflows.
In simple terms:
FlowFile:
It’s basically the data
Comprised of two elements
- Content: the data itself
- Attributes: Key value pairs associated with the data (creation date, filename, etc…)
Gets persisted to disk after creation
Processor:
- Applies a set of transformations and rules to FlowFiles, to generate new FlowFile
- Any processor can process any FlowFile
- Processors are passing FlowFile references to each other to advance the data processing
- They are running in parallel (different threads)
Connector:
It’s basically a queue of all the FlowFiles that are yet to be processed by the next Processor
Defines the rules about how FlowFiles are prioritized (which ones first, which ones not at all)
Can define backpressure to avoid overflow in the system
Categorization of processors:
Over 300+ bundled processors
- Data Transformation: ReplaceText, JoltTransformJSON…
- Routing and Mediation: RouteOnAttribute, RouteOnContent, ControlRate…
- Database Access: ExecuteSQL, ConvertJSONToSQL, PutSQL…
- Attribute Extraction: EvaluateJsonPath, ExtractText, UpdateAttribute…
- System Interaction: ExecuteProcess …
- Data Ingestion: GetFile, GetFTP, GetHTTP, GetHDFS, ListenUDP, GetKafka…
- Sending Data: PutFile, PutFTP, PutKafka, PutEmail…
- Splitting and Aggregation: SplitText, SplitJson, SplitXml, MergeContent…
- HTTP: GetHTTP, ListenHTTP, PostHTTP…
- AWS: FetchS3Object, PutS3Object, PutSNS, GetSQS
FlowFile Topology:
A FlowFile has two components
Attributes:
These are the metadata from the FlowFile
Contain information about the content: e.g. when was it created, where is it from, what data does it represent?
Content:
That’s the actual content of the FlowFile. e.g. it’s the actual content of a file you would read using GetFile
A processor can (either or both):
- Update, add, or remove attributes
- Change content
NiFi Architecture:
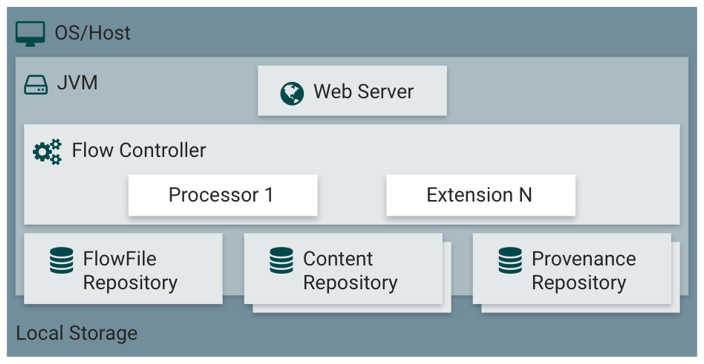
NiFi executes within a JVM on a host operating system.
The primary components of NiFi on the JVM are as follows:
Web Server
The purpose of the web server is to host NiFi’s HTTP-based command and control API.
Flow Controller
The flow controller is the brains of the operation. It provides threads for extensions to run on, and manages the schedule of when extensions receive resources to execute.
Extensions
There are various types of NiFi extensions which are described in other documents. The key point here is that extensions operate and execute within the JVM.
FlowFile Repository
The FlowFile Repository is where NiFi keeps track of the state of what it knows about a given FlowFile that is presently active in the flow. The implementation of the repository is pluggable. The default approach is a persistent Write-Ahead Log located on a specified disk partition.
Content Repository
The Content Repository is where the actual content bytes of a given FlowFile live. The implementation of the repository is pluggable. The default approach is a fairly simple mechanism, which stores blocks of data in the file system. More than one file system storage location can be specified so as to get different physical partitions engaged to reduce contention on any single volume.
Provenance Repository
The Provenance Repository is where all provenance event data is stored. The repository construct is pluggable with the default implementation being to use one or more physical disk volumes. Within each location event data is indexed and searchable.
NiFi is also able to operate within a cluster.
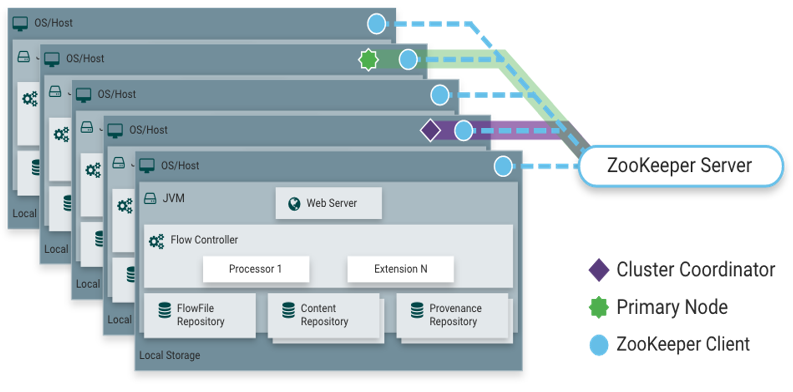
- Starting with the NiFi 1.0 release, a Zero-Master Clustering paradigm is employed.
- Each node in a NiFi cluster performs the same tasks on the data, but each operates on a different set of data.
- Apache ZooKeeper elects a single node as the Cluster Coordinator, and failover is handled automatically by ZooKeeper.
- All cluster nodes report heartbeat and status information to the Cluster Coordinator.
- The Cluster Coordinator is responsible for disconnecting and connecting nodes.
- Additionally, every cluster has one Primary Node, also elected by ZooKeeper.
- As a DataFlow manager, you can interact with the NiFi cluster through the user interface (UI) of any node.
- Any change you make is replicated to all nodes in the cluster, allowing for multiple entry points.
NiFi Downloading and Installation
NiFi can be downloaded from the NiFi Downloads Page. There are two packaging options available: a “tarball” that is tailored more to Linux and a zip file that is more applicable for Windows users
Download NiFi binaries from https://nifi.apache.org/download.html

After download run below commands

Now that NiFi has been started, we can bring up the User Interface (UI) in order to create and monitor our dataflow. To get started, open a web browser and navigate to http://localhost:8080/nifi
This will bring up the User Interface, which at this point is a blank canvas for orchestrating a dataflow:
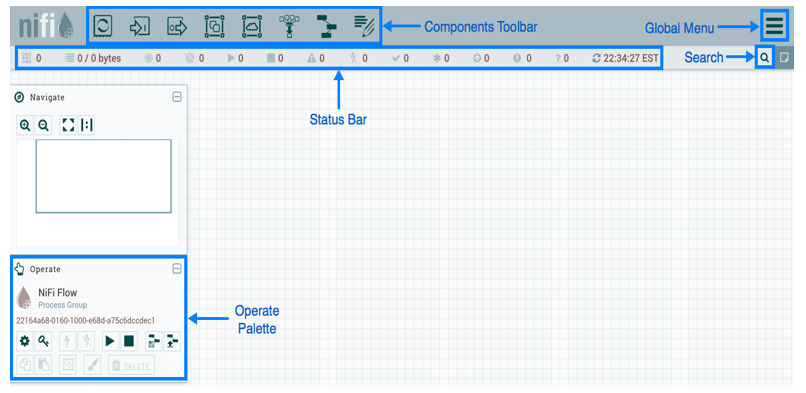
The UI has multiple tools to create and manage your first dataflow:
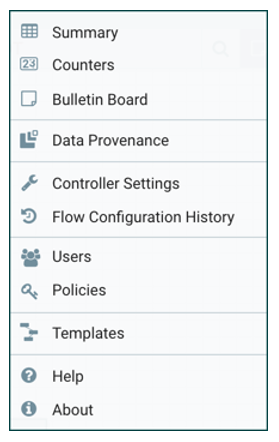
The Global Menu contains the following options:
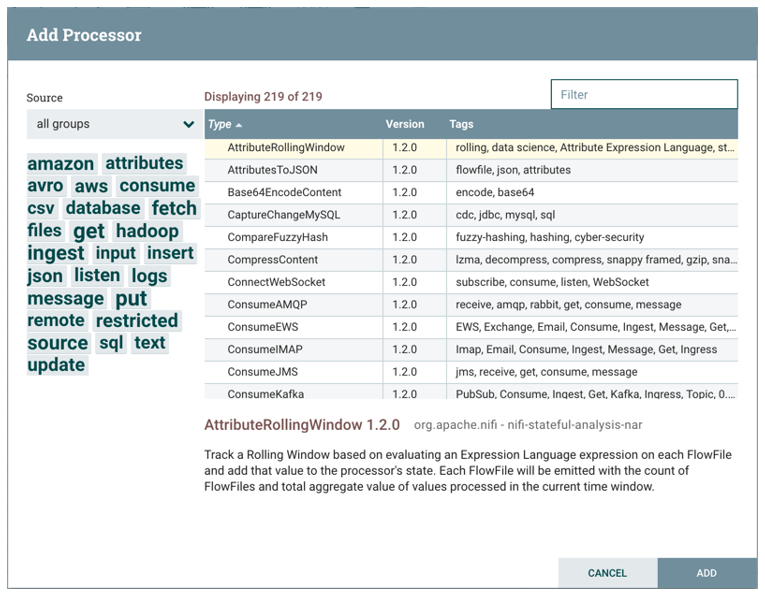
Adding a Processor
We can now begin creating our dataflow by adding a Processor to our canvas. To do this, drag the Processor icon (Processor) from the top-left of the screen into the middle of the canvas (the graph paper-like background) and drop it there. This will give us a dialog that allows us to choose which Processor we want to add:
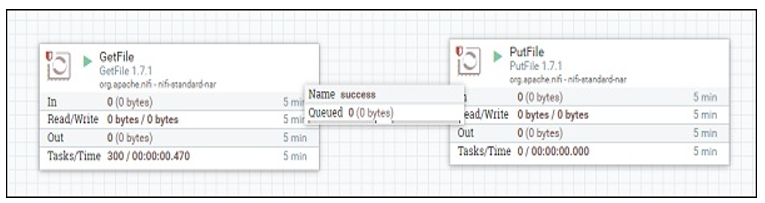
Sample NiFi Process Flow: